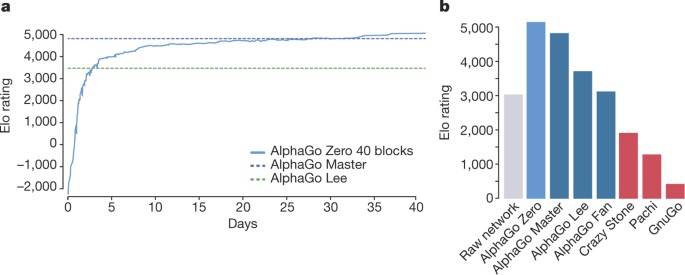
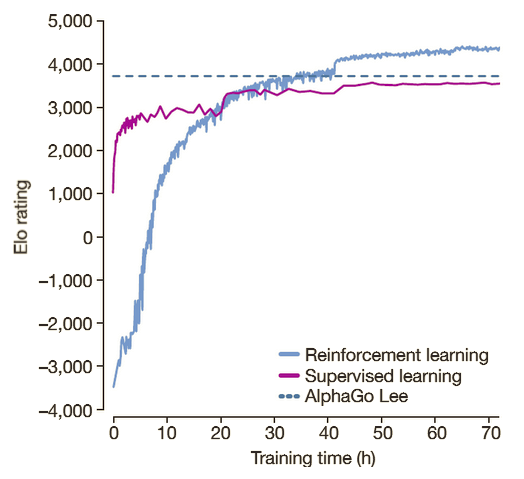
Empirical evaluation of AlphaGo Zero. a Performance of self-play
Por um escritor misterioso
Last updated 22 dezembro 2024
Mastering the game of Go without human knowledge
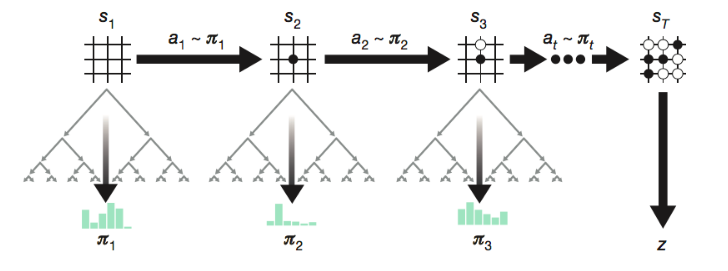
A (Long) Peek into Reinforcement Learning
RLiable: Towards Reliable Evaluation & Reporting in Reinforcement Learning – Google Research Blog

AI versus AI: Self-Taught AlphaGo Zero Vanquishes Its Predecessor
Empirical evaluation of AlphaGo Zero. a Performance of self-play
A (Long) Peek into Reinforcement Learning

Student of Games: A unified learning algorithm for both perfect and imperfect information games

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

neural network - AlphaGo Zero board evaluation function uses multiple time steps as an input Why? - Stack Overflow
Recomendado para você
-
 Google DeepMind's new chess engine beats its famous AlphaZero22 dezembro 2024
Google DeepMind's new chess engine beats its famous AlphaZero22 dezembro 2024 -
 AI AlphaGo Zero started from scratch to become best at Chess, Go and Japanese Chess within hours22 dezembro 2024
AI AlphaGo Zero started from scratch to become best at Chess, Go and Japanese Chess within hours22 dezembro 2024 -
 Chess's New Best Player Is A Fearless, Swashbuckling Algorithm22 dezembro 2024
Chess's New Best Player Is A Fearless, Swashbuckling Algorithm22 dezembro 2024 -
Will AlphaZero become available to the public? - Quora22 dezembro 2024
-
 4050 Elo Rating Performance of AlphaZero, AlphaZero Vs AlphaZero, Chess com, Gotham chess22 dezembro 2024
4050 Elo Rating Performance of AlphaZero, AlphaZero Vs AlphaZero, Chess com, Gotham chess22 dezembro 2024 -
 Prevelo Alpha Zero Review: Why It Earns our Highest Rating22 dezembro 2024
Prevelo Alpha Zero Review: Why It Earns our Highest Rating22 dezembro 2024 -
 Stockfish Robot Teaching Chess Strategy how You can Play like a Grandmaster22 dezembro 2024
Stockfish Robot Teaching Chess Strategy how You can Play like a Grandmaster22 dezembro 2024 -
 AlphaGo Zero Explained22 dezembro 2024
AlphaGo Zero Explained22 dezembro 2024 -
What is the ELO rating of AlphaGo Zero or AlphaZero in chess? - Quora22 dezembro 2024
-
AlphaZero: Shedding new light on chess, shogi, and Go - Google DeepMind22 dezembro 2024

você pode gostar
-
 Bakugan Battle Brawlers (PS3) - Pre-Owned22 dezembro 2024
Bakugan Battle Brawlers (PS3) - Pre-Owned22 dezembro 2024 -
 the rock - Imgflip22 dezembro 2024
the rock - Imgflip22 dezembro 2024 -
 Álbum Fichário Pokémon Eevolutions - aretsanal - com 5 folhas em Promoção na Americanas22 dezembro 2024
Álbum Fichário Pokémon Eevolutions - aretsanal - com 5 folhas em Promoção na Americanas22 dezembro 2024 -
Buy Red Dead Redemption 222 dezembro 2024
-
 Skate De Dedo Brinquedo Infantil 2 Un Divertido Extremo Top22 dezembro 2024
Skate De Dedo Brinquedo Infantil 2 Un Divertido Extremo Top22 dezembro 2024 -
 Stuffed Ziti Fritta, Lunch & Dinner Menu22 dezembro 2024
Stuffed Ziti Fritta, Lunch & Dinner Menu22 dezembro 2024 -
 Who Will Actually Be the Next Superman? An Analysis22 dezembro 2024
Who Will Actually Be the Next Superman? An Analysis22 dezembro 2024 -
Jogo da Velha e Lousa Mágica - Tema Luluca22 dezembro 2024
-
 Fluminense x Sporting Cristal – onde assistir ao vivo, horário do22 dezembro 2024
Fluminense x Sporting Cristal – onde assistir ao vivo, horário do22 dezembro 2024 -
 TOP 5 MELHORES JOGOS DE MOTOS PARA ANDROID 2022!22 dezembro 2024
TOP 5 MELHORES JOGOS DE MOTOS PARA ANDROID 2022!22 dezembro 2024

