Lecture 8: Gradient Descent (and Beyond)
Por um escritor misterioso
Last updated 31 dezembro 2024
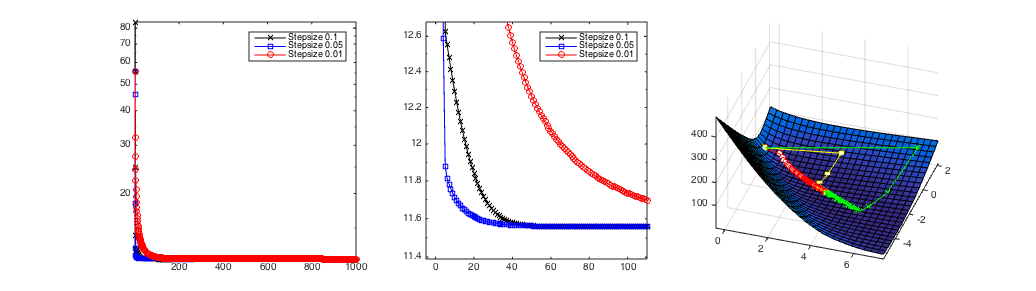

Gradient descent method
Why will gradient descent take longer to reach the global minimum when the features are not on a similar scale? - Quora

An overview of gradient descent optimization algorithms
Minimizing the cost function: Gradient descent, by XuanKhanh Nguyen

Lecture 8: Progress Towards Understanding Generalization in Deep Learning (English)
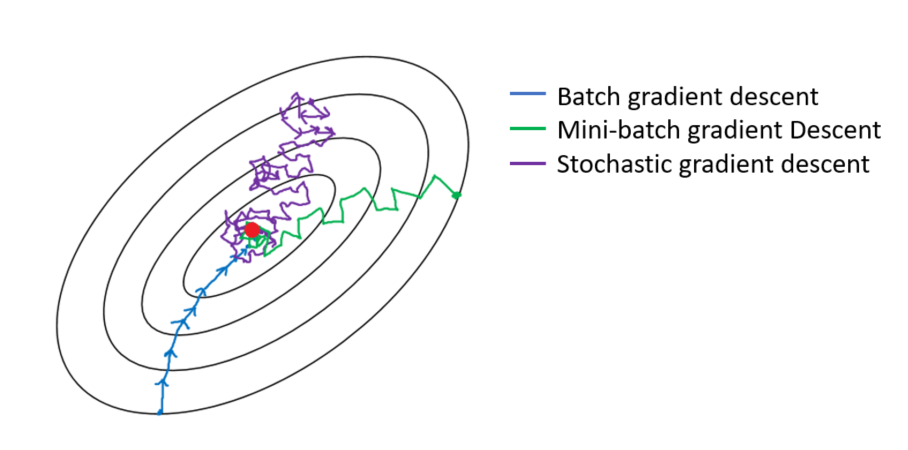
Gradient Descent Algorithm and Its Variants, by Imad Dabbura
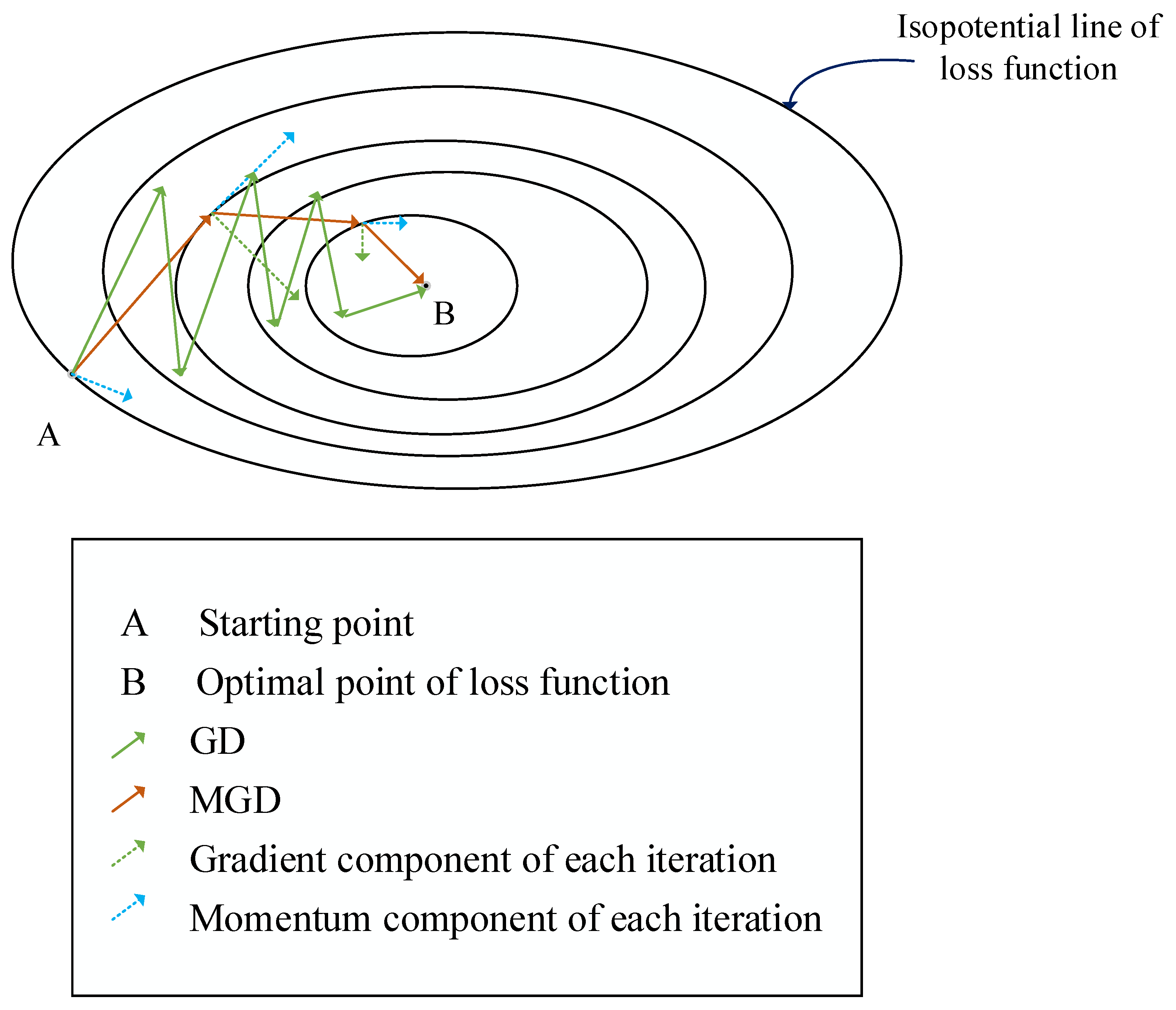
Electronics, Free Full-Text

Gradient Descent. It is a slippery slope, but promise it…, by Hamza Mahmood
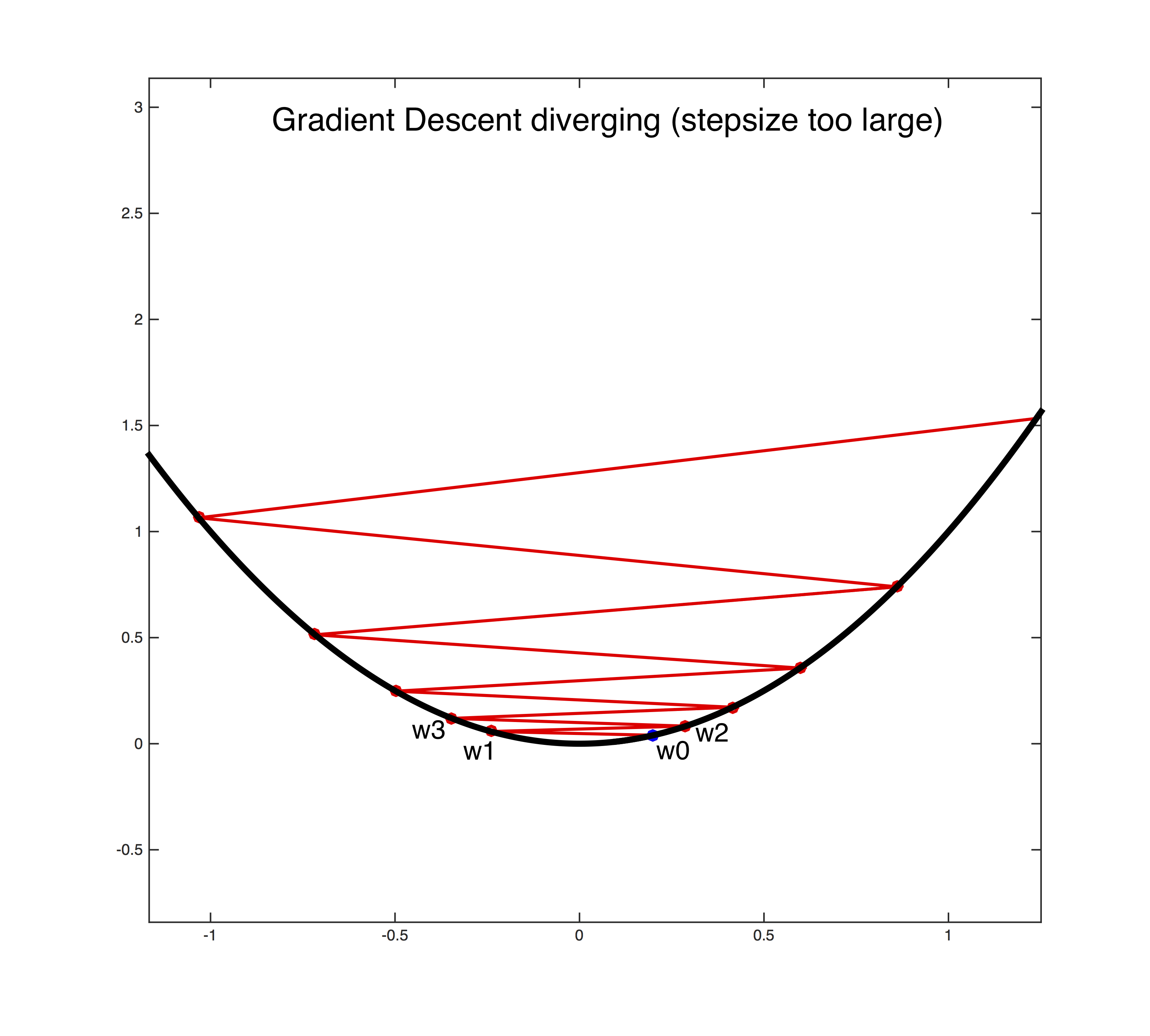
Lecture 8: Gradient Descent (and Beyond)

Linear regression with gradient descent
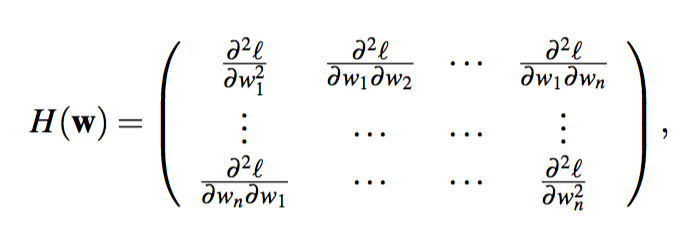
Lecture 7: Gradient Descent (and Beyond)
The flaws of Gradient Descent. Why 'Gradient' and 'Descent' have…, by Sinan Özgün
Recomendado para você
-
 Steepest Descent Method - an overview31 dezembro 2024
Steepest Descent Method - an overview31 dezembro 2024 -
 Introduction to Method of Steepest Descent31 dezembro 2024
Introduction to Method of Steepest Descent31 dezembro 2024 -
 Steepest Descent Method31 dezembro 2024
Steepest Descent Method31 dezembro 2024 -
Gradient descent - Wikipedia31 dezembro 2024
-
 Steepest Descent and Newton's Method in Python, from Scratch: A Comparison, by Nicolo Cosimo Albanese31 dezembro 2024
Steepest Descent and Newton's Method in Python, from Scratch: A Comparison, by Nicolo Cosimo Albanese31 dezembro 2024 -
 Steepest descent method31 dezembro 2024
Steepest descent method31 dezembro 2024 -
 2 The steepest descent method: ) ( ) (k x and ) 2 ( ) ( ) ( k k k e x α31 dezembro 2024
2 The steepest descent method: ) ( ) (k x and ) 2 ( ) ( ) ( k k k e x α31 dezembro 2024 -
 I want to find x solution using Steepest Descent by Python. But when I was running it, it said invalid syntax at def. what should I fix about? - Stack Overflow31 dezembro 2024
I want to find x solution using Steepest Descent by Python. But when I was running it, it said invalid syntax at def. what should I fix about? - Stack Overflow31 dezembro 2024 -
 The Steepest Descent Algorithm. With an implementation in Rust., by applied.math.coding31 dezembro 2024
The Steepest Descent Algorithm. With an implementation in Rust., by applied.math.coding31 dezembro 2024 -
 Steepest Descent - an overview31 dezembro 2024
Steepest Descent - an overview31 dezembro 2024

você pode gostar
-
 filme demon slayer 2023 dublado31 dezembro 2024
filme demon slayer 2023 dublado31 dezembro 2024 -
 Que anime fofinho QUANTO GORE Não sobrou nada, apenas dor31 dezembro 2024
Que anime fofinho QUANTO GORE Não sobrou nada, apenas dor31 dezembro 2024 -
 Halo TV Series Cast Revealed; Release Date Planned for Early 202131 dezembro 2024
Halo TV Series Cast Revealed; Release Date Planned for Early 202131 dezembro 2024 -
Matemática Gis com Giz31 dezembro 2024
-
 Digital Soccer Platform FIFA Plus Launches, 40,000 Live Games Planned31 dezembro 2024
Digital Soccer Platform FIFA Plus Launches, 40,000 Live Games Planned31 dezembro 2024 -
 Preços baixos em Viking Fantasias Para Homens31 dezembro 2024
Preços baixos em Viking Fantasias Para Homens31 dezembro 2024 -
 Watch King of the Hill season 5 episode 12 streaming online31 dezembro 2024
Watch King of the Hill season 5 episode 12 streaming online31 dezembro 2024 -
Watch Record of Grancrest War - Crunchyroll31 dezembro 2024
-
/cdn.vox-cdn.com/uploads/chorus_asset/file/24574516/jlee_230410_1001_pogo_shiny_shellder_cloyster.jpg) Can Shellder be shiny in Pokémon Go? - Polygon31 dezembro 2024
Can Shellder be shiny in Pokémon Go? - Polygon31 dezembro 2024 -
 História Naruto e as Winx, Um Ninja em um Reino de Fadas. - O31 dezembro 2024
História Naruto e as Winx, Um Ninja em um Reino de Fadas. - O31 dezembro 2024
